
|
Research Scientist @ Luma AI Ph.D. in Computer Science, Brown University Email / CV / Google Scholar / Github / LinkedIn / Twitter / Blog |
|
I am a Research Scientist at Luma AI and a core contributor to Uni-1. I received my Ph.D. in Computer Science from Brown University, advised by Professor James Tompkin. During my PhD, I was fortunate to collaborate with Adam Harley, Mikaela Angelina Uy, and Leonidas Guibas from Stanford University. I received my Master in Computer Science from Columbia University, advised by Professor Shuran Song and Professor Shih-Fu Chang. I completed my Bachelor in Computer Science at Fudan University and was a visiting student at MIT EECS (CSAIL). I was a research scientist intern at NVIDIA Research with Abhishek Badki, Hang Su, and Orazio Gallo, and at Meta Reality Labs with Numair Khan, Lei Xiao, and Douglas Lanman. |
|
|
|
|
|
|
|
|
|
|
|
|

|
Luma AI, Tech Lead for Manga 2026 project Uni-1 jointly models time, space, and logic in a single architecture, enabling unified reasoning and visual generation capabilities. |

|
Tianye Ding*, Yiming Xie*, Yiqing Liang*, Moitreya Chatterjee, Pedro Miraldo, Huaizu Jiang CVPR, 2026 project / paper / code We propose LASER, a training-free streaming 4D reconstruction method that aligns scale layer-wise to achieve consistent and accurate spatiotemporal reconstruction from monocular video. |

|
Mike A. Merrill et al. ICLR, 2026 project / paper / code Terminal-Bench provides a comprehensive benchmark of hard, realistic tasks in command line interfaces to evaluate the capabilities of LLM-based agents. |
|
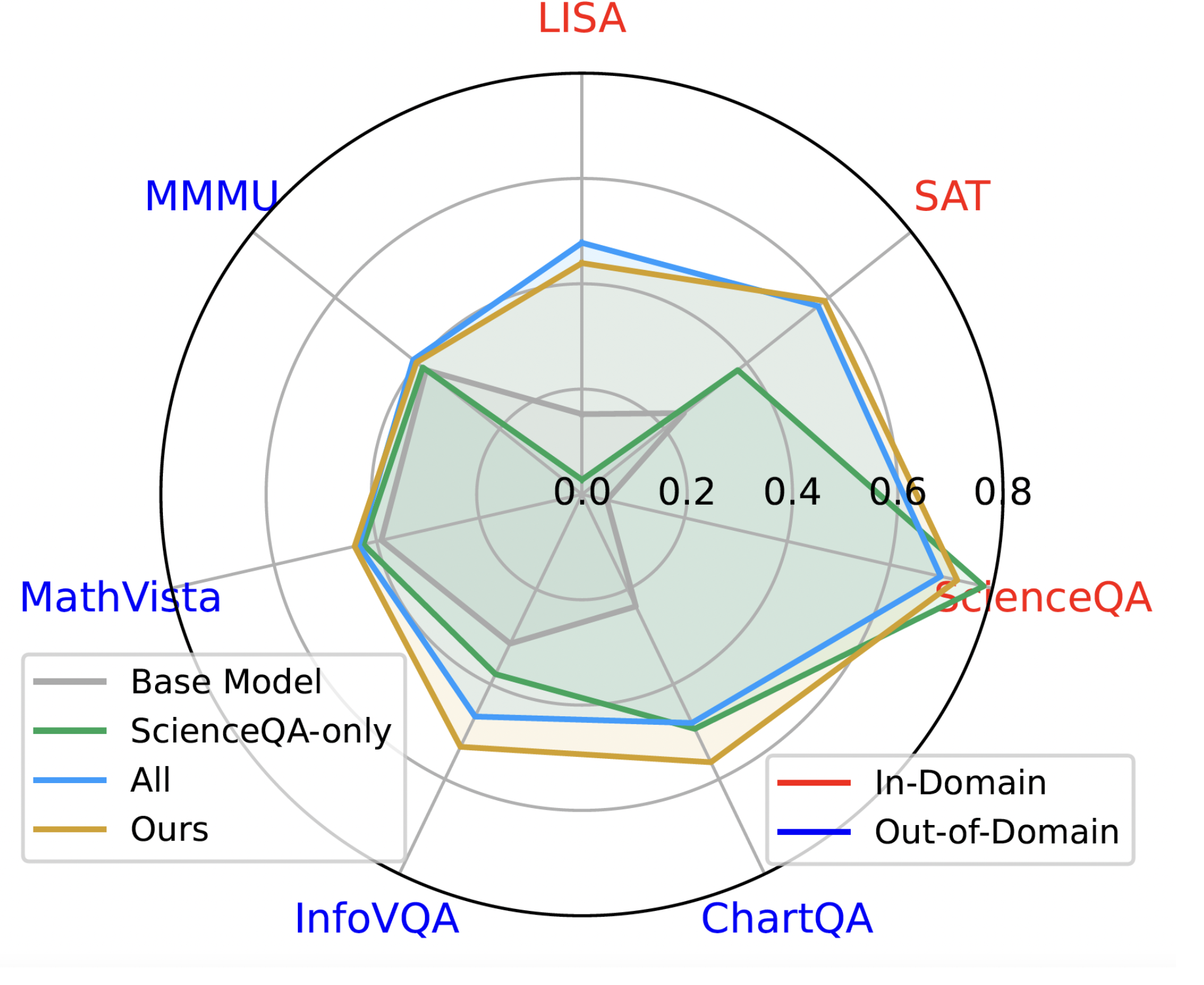
Yiqing Liang, Jielin Qiu, Wenhao Ding, Zuxin Liu, James Tompkin, Mengdi Xu, Mengzhou Xia, Zhengzhong Tu, Laixi Shi, Jiacheng Zhu ICCV 2025 Workshop (MMRAgL), Oral project / paper / data / code / bibtex We introduce MoDoMoDo, a systematic post-training framework for Multimodal LLM RLVR, featuring a rigorous data mixture problem formulation and benchmark implementation. |
|
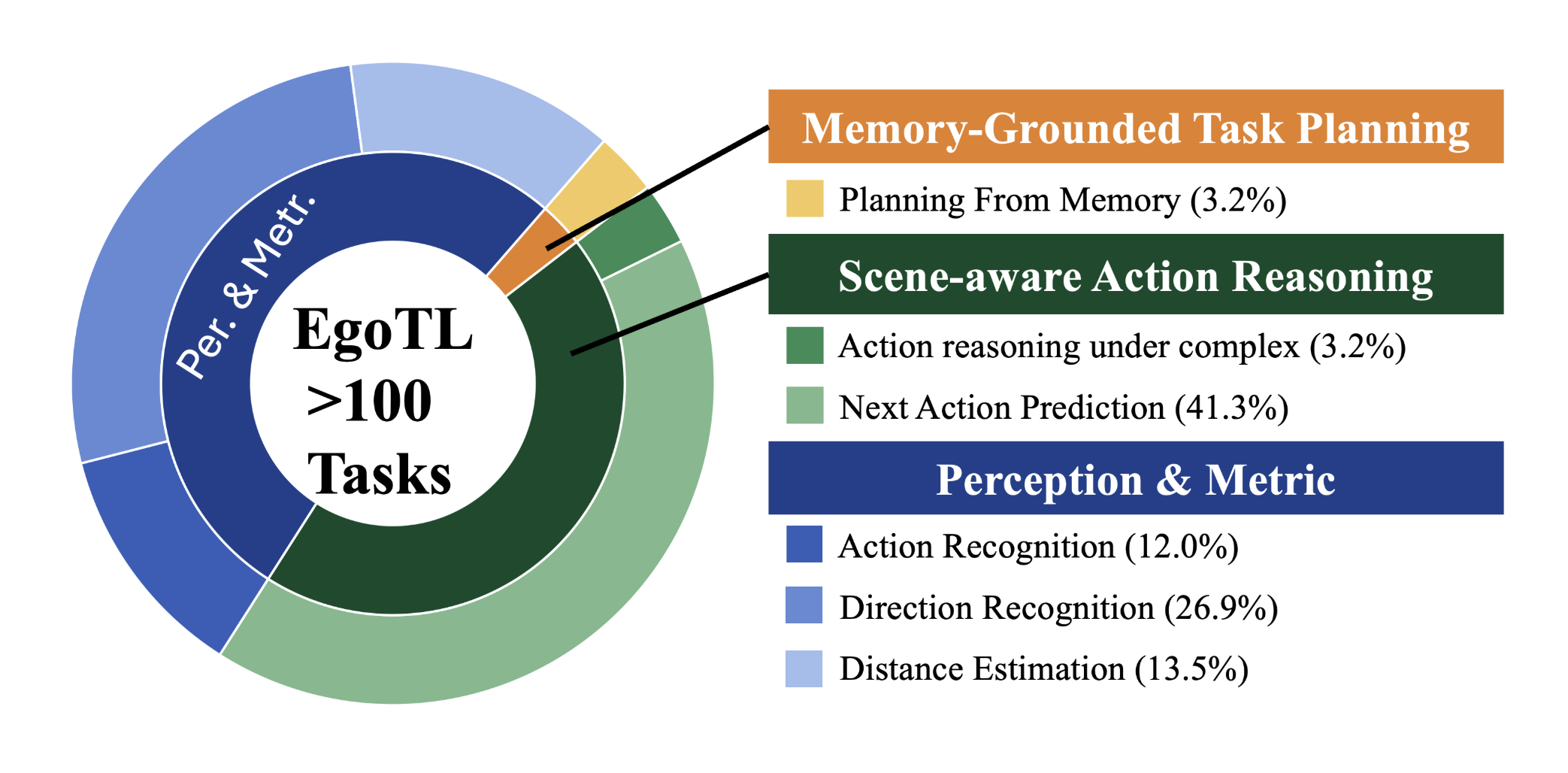
Lulin Liu*, Dayou Li*, Yiqing Liang, Sicong Jiang, Hitesh Vijay, Hezhen Hu, Xuhai Xu, Zirui Liu, Srinivas Shakkottai, Manling Li, Zhiwen Fan CVPR, 2026, Findings Track project EgoTL introduces a think-aloud capture pipeline for egocentric data that records step-by-step goals, spoken reasoning with word-level timestamps, and metric-scale spatial labels, enabling human-aligned supervision for long-horizon egocentric spatial reasoning. |
|
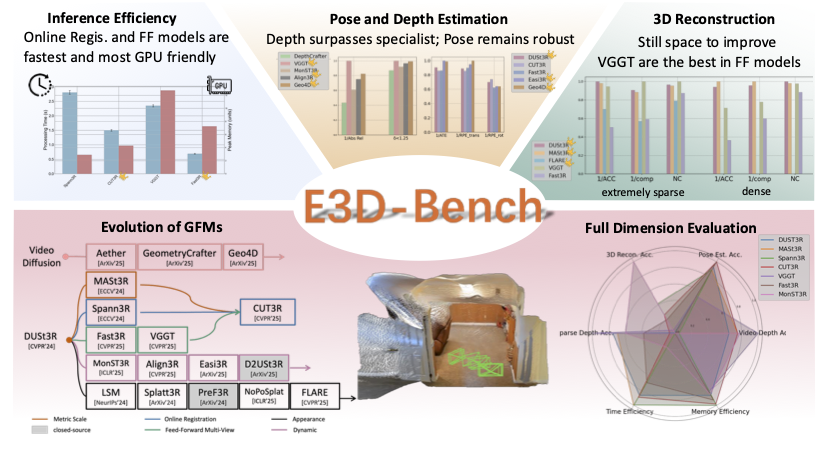
Wenyan Cong, Yiqing Liang, Yancheng Zhang, Ziyi Yang, Yan Wang, Boris Ivanovic, Marco Pavone, Chen Chen, Zhangyang Wang, Zhiwen Fan Under Review, 2025 project / paper / code / bibtex We present the first comprehensive benchmark for 3D end‑to‑end 3D geometric foundation models, covering five core tasks: sparse-view depth estimation, video depth estimation, 3D reconstruction, multi-view pose estimation, novel view synthesis, and spanning both standard and challenging out-of-distribution datasets. |
 
|
Yiqing Liang, Abhishek Badki*, Hang Su*, James Tompkin, Orazio Gallo CVPR, 2025 Oral, Award Candidate (0.48%) project / paper / video / code / bibtex We present ZeroMSF, the first generalizable 3D foundation model that understands monocular scene flow for diverse real-world scenarios, utilizing our curated data recipe of 1M synthetic training samples. |
 
|
Yiqing Liang, Mikhail Okunev, Mikaela Angelina Uy, Runfeng Li, Leonidas J. Guibas, James Tompkin, Adam Harley TMLR, 2025 project / paper / data / code / bibtex We present a benchmark of dynamic Gaussian Splatting methods for monocular view synthesis, combining existing datasets and a new synthetic dataset to provide standardized comparisons and identify key factors affecting efficiency and quality. |
 
|
Yiqing Liang, Numair Khan, Zhengqin Li, Thu Nguyen-Phuoc, Douglas Lanman, James Tompkin, Lei Xiao CVPR, 2024, CV4MR WACV, 2025 project / paper / code / bibtex We propose GauFRe: a dynamic scene reconstruction method using deformable 3D Gaussians for monocular video that is efficient to train, renders in real-time and separates static and dynamic regions. |
|
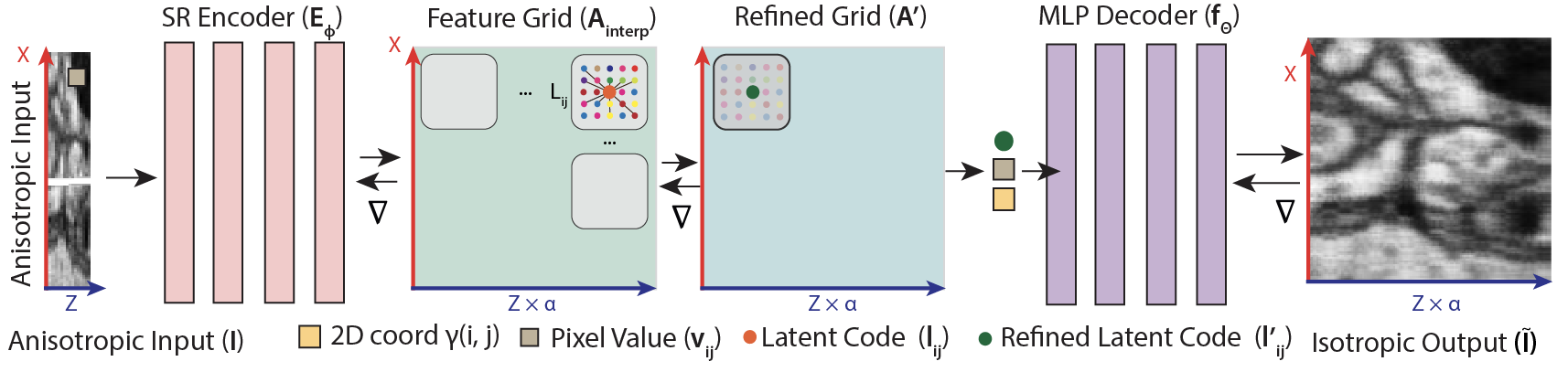
Jakob Troidl, Yiqing Liang, Johanna Beyer, Mojtaba Tavakoli, Johann Danzl, Markus Hadwiger, Hanspeter Pfister, James Tompkin MICCAI Workshop on Efficient Medical AI (EMA), 2025 project / paper / code We propose a self-supervised neural implicit method for reconstructing isotropic 3D volumes from anisotropic microscopy data, achieving +1dB PSNR improvement and 1,000x faster inference over diffusion-based methods. |
|
Yiqing Liang, Eliot Laidlaw, Alexander Meyerowitz, Srinath Sridhar, James Tompkin ICCV, 2023 project / paper / code / bibtex We present SAFF: a dynamic neural volume reconstruction of a casual monocular video that consists of time-varying color, density, scene flow, semantics, and attention information. |
|
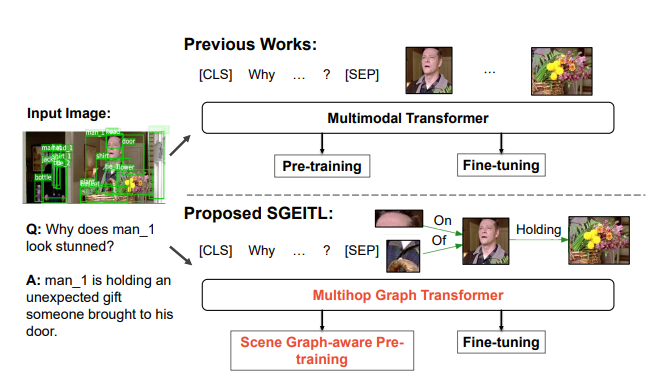
Zhecan Wang*, Haoxuan You*, Liunian Harold Li, Alireza Zareian, Suji Park, Yiqing Liang, Kai-Wei Chang, Shih-Fu Chang AAAI, 2022 paper / bibtex We propose a Scene Graph Enhanced Image-Text Learning (SGEITL) framework to incorporate visual scene graph in commonsense reasoning |
 
|
Yiqing Liang, Boyuan Chen, Shuran Song ICRA, 2021 project / paper / video / code / bibtex We explicitly model scene priors using a confidence-aware semantic scene completion module to complete the scene and guide the agent's navigation planning. |
|
Organizer:
Conference Reviewing: NeurIPS / CVPR / ECCV / ICCV / Eurographics / WACV / IROS / ICRA / AAAI / 3DV Journal Reviewing: TPAMI / RA-L / TVCJ |
|
Based on Jon Barron's template. |