|
|
|
Welcome to my blog! Here I share thoughts on research, technical insights, and explorations in Computer Vision and AI. |
|
|
|
σ(x)
|
November 7, 2025 Technical A comprehensive guide to activation functions in modern deep learning. We explore ReLU, GELU, SiLU/Swish, GLU variants, and SwiGLU, with empirical data on performance, sparsity, and computational costs. Understand why different architectures prefer different activations and make informed choices for your models. Read more → |
|
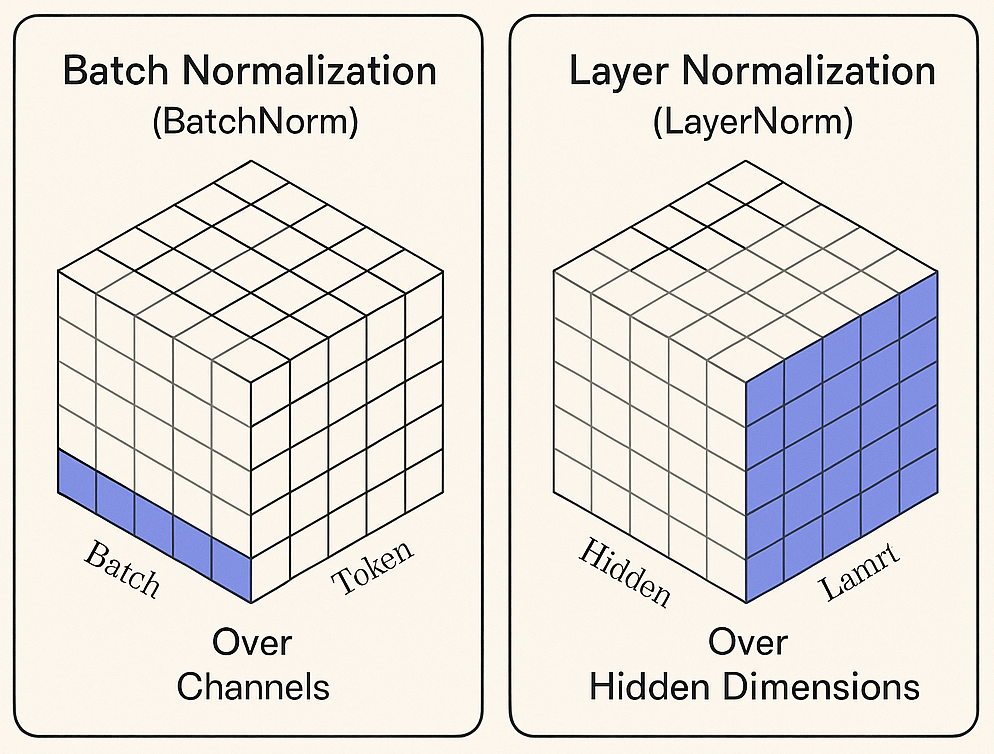
November 6, 2025 Technical A deep dive into why LayerNorm has become the dominant normalization technique in LLMs, VLMs, and Diffusion Transformers, while BatchNorm—once king in CNNs—has largely faded. We explore the fundamental differences, architectural implications, and practical considerations that led to this shift in modern deep learning. Read more → |
|
More posts coming soon... |
|
|